분류와 회귀
분류
분류의 대표적인 방법은 로지스틱 회귀가 있다.
이진 분류
이진 분류는 입력에 대해 두 개의 선택지 중 하나의 답을 선택해야 하는 경우다.
ex) 성적의 합격, 불합격 / 메일의 스팸 유무 등
다중 클래스 분류
다중 클래스 분류는 입력에 대해 세 개 이상의 선택지 중 하나의 답을 선택해야 하는 경우다.
ex) 서점의 카테고리가 과학, 영어, IT, 만화 등이 있고, 이 때 새로운 책의 카테고리를 선택하는 경우
회귀
회귀의 대표적인 방법은 선형 회귀가 있다.
회귀는 연속적인 값의 범위 내에서 예측값이 나오는 경우다.
ex) 부동산 가격 예측, 주가 예측 등
지도 학습과 비지도 학습
지도 학습
지도 학습은 레이블이라는 정답과 함께 학습을 하는 것이다.
자연어 처리는 대부분 지도 학습에 속한다.
예측값과 실제값의 차이인 오차를 줄이는 방식으로 학습을 한다.
비지도 학습
비지도 학습은 데이터에 별도의 레이블 없이 학습하는 것이다.
텍스트 처리 분야의 토픽 모델링 알고리즘인 LSA나 LDA는 비지도 학습에 속한다.
자기지도 학습
레이블이 없는 데이터가 주어졌을 때, 모델이 학습을 위해 스스로 데이터로부터 레이블을 만들어 학습하는 것이다.
Word2Vec과 같은 워드 임베딩 알고리즘, BERT와 같은 언어 모델의 학습 방법들이 예시다.
혼동 행렬
정확도는 결과에 대한 세부적인 내용을 표현할 수는 없다.
이를 위해 혼동 행렬을 사용하고, 아래와 같은 표로 나타낸다.
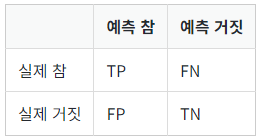
- TP: 실제 True인 정답을 True라고 예측 (정답)
- FP: 실제 False인 정답을 True라고 예측 (오답)
- FN: 실제 True인 정답을 False라고 예측 (오답)
- TN: 실제 False인 정답을 False라고 예측 (정답)
즉, 앞 글자는 정답의 여부, 뒷 글자는 예측한 값을 의미한다.
정밀도
정밀도란 모델이 True라고 분류한 것 중 실제 True인 것의 비율이다.
precision = TP / (TP + FP)
재현율
재현율이란 실제 True인 것 중 모델이 True라고 예측한 것의 비율이다.
recall = TP / (TP + FN)
정밀도와 재현율은 모델이 True라고 예측한 것에 관심이 있다.
정확도
정확도는 가장 많이 사용하는 지표로, 전체 예측 데이터 중 정답을 맞춘 것에 대한 비율이다.
accuracy = (TP + TN) / (TP + FN + FP + FN)
이 지표로 성능을 예측하는 것이 적절하지 않은 경우가 있다.
비가 오는 날을 예측할 때, 200일 중 6일 비가 왔고, 모델은 200일 모두 비가 온다고 예측했다면 정확도는 97%다.
이런 경우를 대비하기 위해 F1-Score를 사용한다.
과적합과 과소 적합
과적합
과적합은 훈련 데이터를 과하게 학습한 경우를 말한다.
과적합 상황에서는 훈련 데이터에 대해서는 오차가 낮지만, 테스트 데이터에 대해서는 오차가 커진다.
과적합을 유발 시키는 이유 중 하나는 에포크 수다.
일정 수치 이상에서 에포크 수가 증가할수록 테스트 데이터에 대한 오차는 점점 증가하는 양상을 보인다.
딥 러닝 시 과적합을 막기 위해서는 Dropout, Early Stopping과 같은 방법을 사용한다.
과소 적합
과소 적합은 테스트 데이터의 성능이 올라갈 여지가 있음에도 훈련을 덜 한 상태를 말한다.
훈련 자체가 부족한 상태이므로 에포크가 지나치게 적으면 발생할 수 있다.
과적합과는 달리 훈련 데이터에 대해서도 정확도가 낮다.
'AI > NLP' 카테고리의 다른 글
| [Wiki] 선형 회귀 (0) | 2024.06.06 |
|---|---|
| [Wiki] 벡터 유사도 (1) | 2024.06.04 |
| [Wiki] 카운트 기반 단어 표현 (1) | 2024.06.03 |
| [Wiki] 언어 모델 (1) | 2024.06.02 |
| [Wiki] 한국어 전처리 패키지 (1) | 2024.06.02 |
분류와 회귀
분류
분류의 대표적인 방법은 로지스틱 회귀가 있다.
이진 분류
이진 분류는 입력에 대해 두 개의 선택지 중 하나의 답을 선택해야 하는 경우다.
ex) 성적의 합격, 불합격 / 메일의 스팸 유무 등
다중 클래스 분류
다중 클래스 분류는 입력에 대해 세 개 이상의 선택지 중 하나의 답을 선택해야 하는 경우다.
ex) 서점의 카테고리가 과학, 영어, IT, 만화 등이 있고, 이 때 새로운 책의 카테고리를 선택하는 경우
회귀
회귀의 대표적인 방법은 선형 회귀가 있다.
회귀는 연속적인 값의 범위 내에서 예측값이 나오는 경우다.
ex) 부동산 가격 예측, 주가 예측 등
지도 학습과 비지도 학습
지도 학습
지도 학습은 레이블이라는 정답과 함께 학습을 하는 것이다.
자연어 처리는 대부분 지도 학습에 속한다.
예측값과 실제값의 차이인 오차를 줄이는 방식으로 학습을 한다.
비지도 학습
비지도 학습은 데이터에 별도의 레이블 없이 학습하는 것이다.
텍스트 처리 분야의 토픽 모델링 알고리즘인 LSA나 LDA는 비지도 학습에 속한다.
자기지도 학습
레이블이 없는 데이터가 주어졌을 때, 모델이 학습을 위해 스스로 데이터로부터 레이블을 만들어 학습하는 것이다.
Word2Vec과 같은 워드 임베딩 알고리즘, BERT와 같은 언어 모델의 학습 방법들이 예시다.
혼동 행렬
정확도는 결과에 대한 세부적인 내용을 표현할 수는 없다.
이를 위해 혼동 행렬을 사용하고, 아래와 같은 표로 나타낸다.
- TP: 실제 True인 정답을 True라고 예측 (정답)
- FP: 실제 False인 정답을 True라고 예측 (오답)
- FN: 실제 True인 정답을 False라고 예측 (오답)
- TN: 실제 False인 정답을 False라고 예측 (정답)
즉, 앞 글자는 정답의 여부, 뒷 글자는 예측한 값을 의미한다.
정밀도
정밀도란 모델이 True라고 분류한 것 중 실제 True인 것의 비율이다.
precision = TP / (TP + FP)
재현율
재현율이란 실제 True인 것 중 모델이 True라고 예측한 것의 비율이다.
recall = TP / (TP + FN)
정밀도와 재현율은 모델이 True라고 예측한 것에 관심이 있다.
정확도
정확도는 가장 많이 사용하는 지표로, 전체 예측 데이터 중 정답을 맞춘 것에 대한 비율이다.
accuracy = (TP + TN) / (TP + FN + FP + FN)
이 지표로 성능을 예측하는 것이 적절하지 않은 경우가 있다.
비가 오는 날을 예측할 때, 200일 중 6일 비가 왔고, 모델은 200일 모두 비가 온다고 예측했다면 정확도는 97%다.
이런 경우를 대비하기 위해 F1-Score를 사용한다.
과적합과 과소 적합
과적합
과적합은 훈련 데이터를 과하게 학습한 경우를 말한다.
과적합 상황에서는 훈련 데이터에 대해서는 오차가 낮지만, 테스트 데이터에 대해서는 오차가 커진다.
과적합을 유발 시키는 이유 중 하나는 에포크 수다.
일정 수치 이상에서 에포크 수가 증가할수록 테스트 데이터에 대한 오차는 점점 증가하는 양상을 보인다.
딥 러닝 시 과적합을 막기 위해서는 Dropout, Early Stopping과 같은 방법을 사용한다.
과소 적합
과소 적합은 테스트 데이터의 성능이 올라갈 여지가 있음에도 훈련을 덜 한 상태를 말한다.
훈련 자체가 부족한 상태이므로 에포크가 지나치게 적으면 발생할 수 있다.
과적합과는 달리 훈련 데이터에 대해서도 정확도가 낮다.
'AI > NLP' 카테고리의 다른 글
| [Wiki] 선형 회귀 (0) | 2024.06.06 |
|---|---|
| [Wiki] 벡터 유사도 (1) | 2024.06.04 |
| [Wiki] 카운트 기반 단어 표현 (1) | 2024.06.03 |
| [Wiki] 언어 모델 (1) | 2024.06.02 |
| [Wiki] 한국어 전처리 패키지 (1) | 2024.06.02 |