코사인 유사도
코사인 유사도는 두 벡터 간의 코사인 각도를 이용해 구한다.

- 두 벡터의 방향이 완전 동일하면 1
- 90도의 각을 이루면 0
- 180도의 반대 방향을 가지면 -1
코사인 유사도를 구하는 식은 아래와 같다.
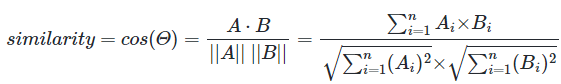
문서 단어 행렬이나 TF-IDF 행렬을 통해 문서의 유사도를 구하는 경우 행렬이 각각의 특징 벡터가 된다.
문서1 : 저는 사과 좋아요
문서2 : 저는 바나나 좋아요
문서3 : 저는 바나나 좋아요 저는 바나나 좋아요
위 예제로 띄어쓰기 기준 토큰화를 한 문서 단어 행렬은 아래와 같다.
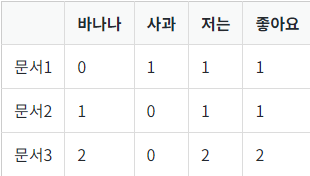
이 표를 토대로 코사인 유사도를 구할 수 있다.
A와 B의 코사인 유사도를 구하면 (1+1) / (루트3)(루트3) = 2/3이 된다.
A와 C의 코사인 유사도를 구하면 (2+2) / (루트3)(루트12) = 2/3이 된다.
B와 C의 코사인 유사도를 구하면 (2+2+2) / (루트3)(루트12) = 1이 된다.
위의 예제를 보면 문서3은 문서2의 단어의 빈도수가 2배임에도 불구하고 유사도가 1이다.
만약 A문서와 B문서는 동일한 주제의 문서이고, C문서는 다른 주제라고 하자.
또, A문서와 C문서는 길이가 유사하고, B문서는 길이가 두 배라고 하자.
이 때, 유클리드 거리로 유사도를 계산하면 문서의 길이의 영향을 받기 때문에 A와 C의 유사도가 더 높을 것이다.
코사인 유사도는 벡터의 방향에 초점을 두므로 문서의 길이가 달라도 비교적 공정한 비교를 할 수 있다.
유클리드 거리
앞서 코사인 유사도와 비교했던 유사도 기법으로 다차원 공간에서 두 개의 점 사이의 거리를 계산하는 것이다.
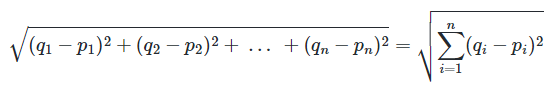
해당 방법은 코사인 유사도 만큼이나 자주 사용되진 않는다.
자카드 유사도
A와 B 두 개의 집합이 있을 때, 합집합에서 교집합의 비율을 구한 것이다.
0과 1 사이의 값을 가지며, 두 집합이 동일하다면 1, 공통 원소가 없다면 0이다.
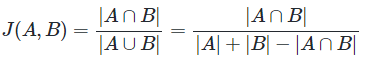
'AI > NLP' 카테고리의 다른 글
| [Wiki] 선형 회귀 (0) | 2024.06.06 |
|---|---|
| [Wiki] 머신 러닝 기본 (0) | 2024.06.06 |
| [Wiki] 카운트 기반 단어 표현 (1) | 2024.06.03 |
| [Wiki] 언어 모델 (1) | 2024.06.02 |
| [Wiki] 한국어 전처리 패키지 (1) | 2024.06.02 |
코사인 유사도
코사인 유사도는 두 벡터 간의 코사인 각도를 이용해 구한다.
- 두 벡터의 방향이 완전 동일하면 1
- 90도의 각을 이루면 0
- 180도의 반대 방향을 가지면 -1
코사인 유사도를 구하는 식은 아래와 같다.
문서 단어 행렬이나 TF-IDF 행렬을 통해 문서의 유사도를 구하는 경우 행렬이 각각의 특징 벡터가 된다.
문서1 : 저는 사과 좋아요
문서2 : 저는 바나나 좋아요
문서3 : 저는 바나나 좋아요 저는 바나나 좋아요
위 예제로 띄어쓰기 기준 토큰화를 한 문서 단어 행렬은 아래와 같다.
이 표를 토대로 코사인 유사도를 구할 수 있다.
A와 B의 코사인 유사도를 구하면 (1+1) / (루트3)(루트3) = 2/3이 된다.
A와 C의 코사인 유사도를 구하면 (2+2) / (루트3)(루트12) = 2/3이 된다.
B와 C의 코사인 유사도를 구하면 (2+2+2) / (루트3)(루트12) = 1이 된다.
위의 예제를 보면 문서3은 문서2의 단어의 빈도수가 2배임에도 불구하고 유사도가 1이다.
만약 A문서와 B문서는 동일한 주제의 문서이고, C문서는 다른 주제라고 하자.
또, A문서와 C문서는 길이가 유사하고, B문서는 길이가 두 배라고 하자.
이 때, 유클리드 거리로 유사도를 계산하면 문서의 길이의 영향을 받기 때문에 A와 C의 유사도가 더 높을 것이다.
코사인 유사도는 벡터의 방향에 초점을 두므로 문서의 길이가 달라도 비교적 공정한 비교를 할 수 있다.
유클리드 거리
앞서 코사인 유사도와 비교했던 유사도 기법으로 다차원 공간에서 두 개의 점 사이의 거리를 계산하는 것이다.
해당 방법은 코사인 유사도 만큼이나 자주 사용되진 않는다.
자카드 유사도
A와 B 두 개의 집합이 있을 때, 합집합에서 교집합의 비율을 구한 것이다.
0과 1 사이의 값을 가지며, 두 집합이 동일하다면 1, 공통 원소가 없다면 0이다.
'AI > NLP' 카테고리의 다른 글
| [Wiki] 선형 회귀 (0) | 2024.06.06 |
|---|---|
| [Wiki] 머신 러닝 기본 (0) | 2024.06.06 |
| [Wiki] 카운트 기반 단어 표현 (1) | 2024.06.03 |
| [Wiki] 언어 모델 (1) | 2024.06.02 |
| [Wiki] 한국어 전처리 패키지 (1) | 2024.06.02 |