BoW(Bag of Words)
단어의 순서는 고려하지 않고 출현 빈도에만 집중하는 텍스트 데이터의 수치화 표현 방법이다.
- 정수 인덱싱 (단어 집합 생성)
- 각 인덱스의 위치에 단어 토큰의 등장 횟수를 기록한 벡터 생성
from konlpy.tag import Okt
okt = Okt()
def build_bag_of_words(document):
document = document.replace('.', '')
tokenized_document = okt.morphs(document)
word_to_index = {}
bow = []
for word in tokenized_document:
if word not in word_to_index.keys():
word_to_index[word] = len(word_to_index)
bow.insert(len(word_to_index) - 1, 1)
else:
index = word_to_index.get(word)
bow[index] = bow[index] + 1
return word_to_index, bow
doc1 = "정부가 발표하는 물가상승률과 소비자가 느끼는 물가상승률은 다르다."
vocab, bow = build_bag_of_words(doc1)
print('vocabulary :', vocab)
print('bag of words vector :', bow)
'''
vocabulary : {'정부': 0, '가': 1, '발표': 2, '하는': 3, '물가상승률': 4, '과': 5, '소비자': 6, '느끼는': 7, '은': 8, '다르다': 9}
bag of words vector : [1, 2, 1, 1, 2, 1, 1, 1, 1, 1]
'''
'가'와 '물가상승률'은 두 번 등장하여 해당 인덱스 위치에 값은 2이다.
어떤 단어가 얼마나 등장했는지를 기준으로 어떤 성격의 문서인지를 판단하는 작업에 쓰인다.
여러 문서 간의 유사도를 구할 때도 쓰인다.
사이킷 런
CountVectorizer
단어의 빈도를 Count 하여 Vector로 만드는 CountVectorizer 클래스를 지원한다.
from sklearn.feature_extraction.text import CountVectorizer
corpus = ['you know I want your love. because I love you.']
vector = CountVectorizer()
print('bag of words vector :', vector.fit_transform(corpus).toarray())
print('vocabulary :',vector.vocabulary_)
'''
bag of words vector : [[1 1 2 1 2 1]]
vocabulary : {'you': 4, 'know': 1, 'want': 3, 'your': 5, 'love': 2, 'because': 0}
'''
CountVectorizer는 띄어쓰기만을 기준으로 토큰화를 진행한다.
별도의 정제 작업도 거치지 않기 때문에 복잡한 영어 문장에도 추가적인 작업이 필요할 것이다.
한글의 경우 조사나 접사 등의 이유로 BoW가 제대로 만들어지지 않을 것이다.
불용어 제거한 BoW
CountVecotizer의 stop_words 인자를 이용하면 쉽게 불용어를 제거할 수 있다.
리스트의 값을 주어 사용자가 정의한 불용어를 명시할 수도 있고,
"english" 값을 주어 자체 제공하는 불용어를 사용할 수도 있다.
stop_words = stopwords.words("english")
해당 코드로 NLTK에서 지원하는 불용어를 사용할 수도 있다.
DTM
다수의 문서에 등장하는 각 단어들의 빈도를 행렬로 표현한 것이다.
문서들을 서로 비교할 수 있도록 수치화할 수 있다는 점에서 의의를 갖는다.
한계
희소 표현
원-핫 벡터와 동일하게 공간적 낭비와 계산 리소스를 증가시킨다는 단점을 갖는다.
리처럼 대부분의 값이 0인 표현을 희소 벡터, 희소 행렬이라고 한다.
구두점, 빈도수 낮은 단어, 불용어 제거, 어간 추출 등 전처리를 통해 단어의 집합 크기를 줄여야 한다.
단순 빈도 수 기반 접근
the와 같은 단어는 모든 문장에 자주 등장한다.
이 the의 빈도수가 높다고 해서 해당 문서들을 유사한 문서라고 판단할 수 없다.
불용어와 중요한 단어에 대해 가중치를 주어 해결하는 방법이 있다.
TF-IDF
단어의 빈도와 역 문서 빈도를 사용하여 각 단어들마다 중요한 정도를 가중치로 준느 방법이다.
문서의 유사도, 검색 결과의 중요도, 문서 내 특정 단어 중요도를 구하는 작업에 쓰인다.
TF-IDF는 TF와 IDF를 곱한 값이다.
- d: 문서
- t: 단어
- n: 문서 개수
tf(d, f)
특정 문서 d에서 특정 단어 t의 등장 횟수다.
df(t)
특정 단어 t가 등장한 문서의 수다.
특정 단어가 어떤 문서에 등장했는지, 몇 번 등장했는지는 신경쓰지 않는다.
문서1에 t가 200번, 문서2에 t가 400번 등장하더라도 df(t)는 2이다.
idf(t)
df(t)에 반비례하는 수다.
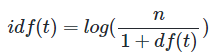
그냥 역수를 취하게 되면 n이 커질수록 IDF의 값이 기하급수적으로 커진다.
따라서 log를 씌워준다. 또, log를 씌워야 희귀 단어들에 엄청난 가중치가 부여되지 않을 수 있다.
분모가 0이 됨을 방지하기 위해 1을 더해준다.
TF-IDF는 모든 문서에서 자주 등장하는 단어는 중요도가 낮다고 판단한다.
특정 문서에만 자주 등장하는 단어는 중요도가 높다고 판단한다.
TF-IDF 값과 중요도는 비례한다.
문제점
df(t) = n - 1이라면 log1이 되고 가중치가 0이 된다.
따라서 TD-IDF 구현을 제공하는 패키지들은 조정된 식을 사용한다.
사이킷 런
CountVectorizer
위에서 사용했던 CountVectorizer를 사용해 DTM을 생성할 수 있다.
from sklearn.feature_extraction.text import CountVectorizer
corpus = [
'you know I want your love',
'I like you',
'what should I do ',
]
vector = CountVectorizer()
print(vector.fit_transform(corpus).toarray())
'''
[[0 1 0 1 0 1 0 1 1]
[0 0 1 0 0 0 0 1 0]
[1 0 0 0 1 0 1 0 0]]
'''
TfidfVectorizer
TF-IDF를 자동으로 계산해준다.
이 때는 TF-IDF의 조정된 식을 사용한다.
IDF의 로그항의 분자에 1을 더해주고, 로그항에 1을 더한다.
from sklearn.feature_extraction.text import TfidfVectorizer
corpus = [
'you know I want your love',
'I like you',
'what should I do ',
]
tfidfv = TfidfVectorizer().fit(corpus)
print(tfidfv.transform(corpus).toarray())
print(tfidfv.vocabulary_)
'''
[[0. 0.46735098 0. 0.46735098 0. 0.46735098 0. 0.35543247 0.46735098]
[0. 0. 0.79596054 0. 0. 0. 0. 0.60534851 0. ]
[0.57735027 0. 0. 0. 0.57735027 0. 0.57735027 0. 0. ]]
{'you': 7, 'know': 1, 'want': 5, 'your': 8, 'love': 3, 'like': 2, 'what': 6, 'should': 4, 'do': 0}
'''
'AI > NLP' 카테고리의 다른 글
| [Wiki] 머신 러닝 기본 (0) | 2024.06.06 |
|---|---|
| [Wiki] 벡터 유사도 (1) | 2024.06.04 |
| [Wiki] 언어 모델 (1) | 2024.06.02 |
| [Wiki] 한국어 전처리 패키지 (1) | 2024.06.02 |
| [Wiki] 원-핫 인코딩 (0) | 2024.06.02 |
BoW(Bag of Words)
단어의 순서는 고려하지 않고 출현 빈도에만 집중하는 텍스트 데이터의 수치화 표현 방법이다.
- 정수 인덱싱 (단어 집합 생성)
- 각 인덱스의 위치에 단어 토큰의 등장 횟수를 기록한 벡터 생성
from konlpy.tag import Okt
okt = Okt()
def build_bag_of_words(document):
document = document.replace('.', '')
tokenized_document = okt.morphs(document)
word_to_index = {}
bow = []
for word in tokenized_document:
if word not in word_to_index.keys():
word_to_index[word] = len(word_to_index)
bow.insert(len(word_to_index) - 1, 1)
else:
index = word_to_index.get(word)
bow[index] = bow[index] + 1
return word_to_index, bow
doc1 = "정부가 발표하는 물가상승률과 소비자가 느끼는 물가상승률은 다르다."
vocab, bow = build_bag_of_words(doc1)
print('vocabulary :', vocab)
print('bag of words vector :', bow)
'''
vocabulary : {'정부': 0, '가': 1, '발표': 2, '하는': 3, '물가상승률': 4, '과': 5, '소비자': 6, '느끼는': 7, '은': 8, '다르다': 9}
bag of words vector : [1, 2, 1, 1, 2, 1, 1, 1, 1, 1]
'''
'가'와 '물가상승률'은 두 번 등장하여 해당 인덱스 위치에 값은 2이다.
어떤 단어가 얼마나 등장했는지를 기준으로 어떤 성격의 문서인지를 판단하는 작업에 쓰인다.
여러 문서 간의 유사도를 구할 때도 쓰인다.
사이킷 런
CountVectorizer
단어의 빈도를 Count 하여 Vector로 만드는 CountVectorizer 클래스를 지원한다.
from sklearn.feature_extraction.text import CountVectorizer
corpus = ['you know I want your love. because I love you.']
vector = CountVectorizer()
print('bag of words vector :', vector.fit_transform(corpus).toarray())
print('vocabulary :',vector.vocabulary_)
'''
bag of words vector : [[1 1 2 1 2 1]]
vocabulary : {'you': 4, 'know': 1, 'want': 3, 'your': 5, 'love': 2, 'because': 0}
'''
CountVectorizer는 띄어쓰기만을 기준으로 토큰화를 진행한다.
별도의 정제 작업도 거치지 않기 때문에 복잡한 영어 문장에도 추가적인 작업이 필요할 것이다.
한글의 경우 조사나 접사 등의 이유로 BoW가 제대로 만들어지지 않을 것이다.
불용어 제거한 BoW
CountVecotizer의 stop_words 인자를 이용하면 쉽게 불용어를 제거할 수 있다.
리스트의 값을 주어 사용자가 정의한 불용어를 명시할 수도 있고,
"english" 값을 주어 자체 제공하는 불용어를 사용할 수도 있다.
stop_words = stopwords.words("english")
해당 코드로 NLTK에서 지원하는 불용어를 사용할 수도 있다.
DTM
다수의 문서에 등장하는 각 단어들의 빈도를 행렬로 표현한 것이다.
문서들을 서로 비교할 수 있도록 수치화할 수 있다는 점에서 의의를 갖는다.
한계
희소 표현
원-핫 벡터와 동일하게 공간적 낭비와 계산 리소스를 증가시킨다는 단점을 갖는다.
리처럼 대부분의 값이 0인 표현을 희소 벡터, 희소 행렬이라고 한다.
구두점, 빈도수 낮은 단어, 불용어 제거, 어간 추출 등 전처리를 통해 단어의 집합 크기를 줄여야 한다.
단순 빈도 수 기반 접근
the와 같은 단어는 모든 문장에 자주 등장한다.
이 the의 빈도수가 높다고 해서 해당 문서들을 유사한 문서라고 판단할 수 없다.
불용어와 중요한 단어에 대해 가중치를 주어 해결하는 방법이 있다.
TF-IDF
단어의 빈도와 역 문서 빈도를 사용하여 각 단어들마다 중요한 정도를 가중치로 준느 방법이다.
문서의 유사도, 검색 결과의 중요도, 문서 내 특정 단어 중요도를 구하는 작업에 쓰인다.
TF-IDF는 TF와 IDF를 곱한 값이다.
- d: 문서
- t: 단어
- n: 문서 개수
tf(d, f)
특정 문서 d에서 특정 단어 t의 등장 횟수다.
df(t)
특정 단어 t가 등장한 문서의 수다.
특정 단어가 어떤 문서에 등장했는지, 몇 번 등장했는지는 신경쓰지 않는다.
문서1에 t가 200번, 문서2에 t가 400번 등장하더라도 df(t)는 2이다.
idf(t)
df(t)에 반비례하는 수다.
그냥 역수를 취하게 되면 n이 커질수록 IDF의 값이 기하급수적으로 커진다.
따라서 log를 씌워준다. 또, log를 씌워야 희귀 단어들에 엄청난 가중치가 부여되지 않을 수 있다.
분모가 0이 됨을 방지하기 위해 1을 더해준다.
TF-IDF는 모든 문서에서 자주 등장하는 단어는 중요도가 낮다고 판단한다.
특정 문서에만 자주 등장하는 단어는 중요도가 높다고 판단한다.
TF-IDF 값과 중요도는 비례한다.
문제점
df(t) = n - 1이라면 log1이 되고 가중치가 0이 된다.
따라서 TD-IDF 구현을 제공하는 패키지들은 조정된 식을 사용한다.
사이킷 런
CountVectorizer
위에서 사용했던 CountVectorizer를 사용해 DTM을 생성할 수 있다.
from sklearn.feature_extraction.text import CountVectorizer
corpus = [
'you know I want your love',
'I like you',
'what should I do ',
]
vector = CountVectorizer()
print(vector.fit_transform(corpus).toarray())
'''
[[0 1 0 1 0 1 0 1 1]
[0 0 1 0 0 0 0 1 0]
[1 0 0 0 1 0 1 0 0]]
'''
TfidfVectorizer
TF-IDF를 자동으로 계산해준다.
이 때는 TF-IDF의 조정된 식을 사용한다.
IDF의 로그항의 분자에 1을 더해주고, 로그항에 1을 더한다.
from sklearn.feature_extraction.text import TfidfVectorizer
corpus = [
'you know I want your love',
'I like you',
'what should I do ',
]
tfidfv = TfidfVectorizer().fit(corpus)
print(tfidfv.transform(corpus).toarray())
print(tfidfv.vocabulary_)
'''
[[0. 0.46735098 0. 0.46735098 0. 0.46735098 0. 0.35543247 0.46735098]
[0. 0. 0.79596054 0. 0. 0. 0. 0.60534851 0. ]
[0.57735027 0. 0. 0. 0.57735027 0. 0.57735027 0. 0. ]]
{'you': 7, 'know': 1, 'want': 5, 'your': 8, 'love': 3, 'like': 2, 'what': 6, 'should': 4, 'do': 0}
'''
'AI > NLP' 카테고리의 다른 글
| [Wiki] 머신 러닝 기본 (0) | 2024.06.06 |
|---|---|
| [Wiki] 벡터 유사도 (1) | 2024.06.04 |
| [Wiki] 언어 모델 (1) | 2024.06.02 |
| [Wiki] 한국어 전처리 패키지 (1) | 2024.06.02 |
| [Wiki] 원-핫 인코딩 (0) | 2024.06.02 |